

Bittensor: P2Pのインテリジェンス市場
YUMA RAO
- 00 / Abstract 要約
- 0.1 / Introduction はじめに
- 01 / Model モデル
- 02 / Incentive インセンティブ
- 03 / Bonds 債券
- 04 / Reaching consensus 合意形成
- 05 / Running the network ネットワークの実行
- 06 / Tensor standardization テンソルの標準化
- 07 / Conditional computation 条件付き計算
- 08 / Knowledge extraction 知識の抽出
- 09 / Learning weights 学習ウェイト
- 10 / Collusion 結託
- 11 / Conclusion 結論
- こちらの記事もどうぞ
00 / Abstract 要約

他のコモディティと同様に、市場はマシンインテリジェンスを効率的に生産するのに役立つ可能性がある。我々は、知能が他の知能システムに対してインターネットを介してピアツーピアで価格設定される市場を提案している。ピアは、隣接する知能の価値を学習するニューラルネットワークをトレーニングすることによって互いに評価する。スコアはデジタル台帳に蓄積され、高評価のピアはネットワーク内で追加のウェイトで報酬を受け取る。ただし、この種のピア評価は結託に対して耐性を持たないため、メカニズムの正確さを妨げる可能性がある。解決策は、公正に選択されたウェイトを最大限に報酬するインセンティブメカニズムで、ネットワークウェイトの50パーセントまでの結託に耐性を持たせるものです。その結果、新しくトレーニングされたモデルを継続的に生産し、情報理論的な価値を創造する貢献者に報酬を支払う共同運営型の知能市場が生まれる。
0.1 / Introduction はじめに

マシンインテリジェンスの生産は、ほとんど完全にベンチマークシステムに依存するようになりました。ここでは、機械学習モデルが狭義に定義された監視された問題で優れたパフォーマンスを発揮するために訓練される。このシステムは、これらの特定の問題でのパフォーマンスを向上させるのには適しているが、市場の導入によってその能力を発揮できる状況では弱点がある。例えば、知能はますます特定の目標から解き放たれ、データから貴重な資源として採掘される(Schwartz et al. [2019])、金銭的価値がある(OpenAI [2020])、転送可能である(Devlin et al. [2019])、そして一般的に有用である(Radford et al. [2019])ようになっている。監視された目標でその生産を測定することは、その資源そのものに直接報酬を与えず、分野が狭義の専門家に収束する原因となる(Chollet [2019])。さらに、これらの目標(精度などの単一次元のメトリクスでよく測定される)は、ニッチなシステムや既存のシステムに報酬を与える解像度を持っていないため、現行の最先端技術でないものは失われてしまう。結局、多様な知能システムの普及は、勝者総取りの競争に成功するために大規模な一体型モデルを訓練する必要があるために制限されている。単独のエンジニアは直接に自分の仕事を収益化することができず、その結果、少数の大手企業が最高の人工知能へのアクセスを支配する中央集権化が生じている(OpenAI [2020])。

新しいコモディティには新しいタイプの市場が必要です。このホワイトペーパーでは、マシンインテリジェンスが他の知能システムによって評価される枠組みを提案している。モデルは、それらを訓練するために使用された主観的なタスクやデータセットに関係なく、情報生産のためにランク付けされる。マシンインテリジェンスの評価基準を変更することにより、(1)市場ははるかに多くの目標に適用可能な知能を報酬とすることができ、(2)既存のシステムはその独自の価値に対して収益化され、(3)より高い解像度の報酬環境内でさまざまな小規模なシステムがニッチを見つけることができる。解決策は、連続的かつ非同期的な方法で互いに表現を共有するコンピュータネットワーク、インターネットを介したピアツーピア(P2P)です。構築された市場はデジタル台帳を使用してランクを記録し、分散型の方法でピアにインセンティブを提供する。このチェーンは信頼を測定し、多数派に価値を提供しないで報酬を得るのが難しくなる。研究者は直接マシンインテリジェンスの作業を収益化し、消費者はそれを直接購入できる。
01 / Model モデル

我々は、ヒントンらによる知能の抽象的な定義から始める。[2015]
データセット D = [X,Y] に対して、損失 L = ED[Q(y,f(x))] を最小化するようにトレーニングされたパラメータ化された関数y = f(x)の形式で表している。我々のネットワークは、n個の関数F = f0,…,fj,…fn「ピア」で構成され、それぞれがデジタル台帳上に表現されたゼロ以上のネットワークウェイト S = [Si] 「ステーク」を保持している。これらの関数は、損失とそのステークの割合とともに、ステーク加重 された機械学習目標 Σni Li, * si を表す。

図1 / 損失 Li と固有のデータセット Di を伴うピア関数
 我々の目標は、損失を最小化することに貢献したピアにインセンティブとしてステーク I を分配することであり(図1)、重要なことは、損失を最小化することなくネットワーク内での分配を最大化する手段として、少数のステーク割合が結託することが困難であるようにすることである(図3)。
我々の目標は、損失を最小化することに貢献したピアにインセンティブとしてステーク I を分配することであり(図1)、重要なことは、損失を最小化することなくネットワーク内での分配を最大化する手段として、少数のステーク割合が結託することが困難であるようにすることである(図3)。
 本ホワイトペーパーでは、ピアランキングを通じて達成できることを提案する。ピアは他の人の出力 F(x) = [f0(x)…fn(x)] を自分自身への入力として使用し、 f(F(x))ウェイトのセット W = [wi,j] を学習する。ピア i は、デジタル台帳上のトランザクションを通じて i 番目の行を設定する責任がある。
本ホワイトペーパーでは、ピアランキングを通じて達成できることを提案する。ピアは他の人の出力 F(x) = [f0(x)…fn(x)] を自分自身への入力として使用し、 f(F(x))ウェイトのセット W = [wi,j] を学習する。ピア i は、デジタル台帳上のトランザクションを通じて i 番目の行を設定する責任がある。
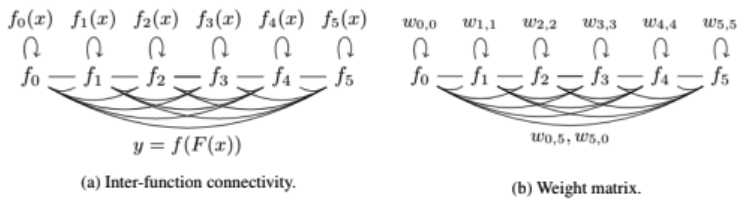
 ルカンらによるフィッシャーズ・インフォメーション・プルーニング・スコアを用いたウェイトの設定。[1989];Yu et al. [2017]
ルカンらによるフィッシャーズ・インフォメーション・プルーニング・スコアを用いたウェイトの設定。[1989];Yu et al. [2017]
ランキングの計算において、R = WT.S は、各ピアのインセンティブがそのプルーニング・スコアと等価である理想化されたスコアリングを達成する:ネットワークからそれを削除することによって誘導される Σni Li * Si に対するエントロピーのコストである。
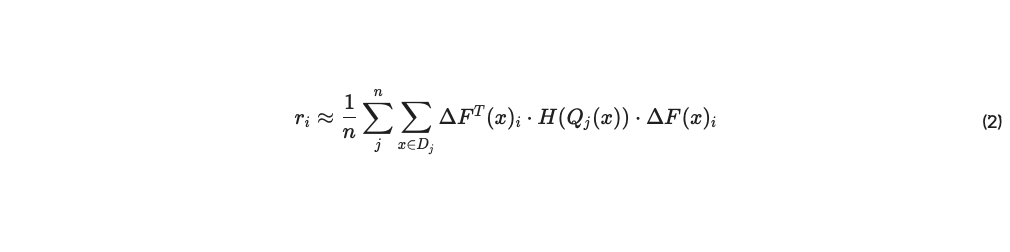
 しかし、この方法は結託には強くない、 この場合、ピアは(2)の代わりに自分自身に投票し、ネットワークを犠牲にして自分自身のインフレを高めるようにウェイトを設定する(図3)。デジタル台帳は各モデルのパラメータを監査できず、モデル間のウェイト W のみを監査できるため、この攻撃は簡単である。
しかし、この方法は結託には強くない、 この場合、ピアは(2)の代わりに自分自身に投票し、ネットワークを犠牲にして自分自身のインフレを高めるようにウェイトを設定する(図3)。デジタル台帳は各モデルのパラメータを監査できず、モデル間のウェイト W のみを監査できるため、この攻撃は簡単である。
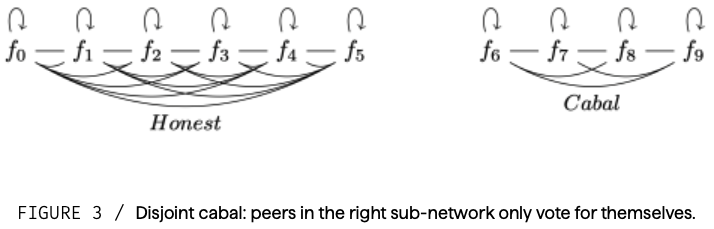
図3 / 分裂組織:右のサブネットワークのピアは、自分のためだけに投票する。
02 / Incentive インセンティブ
 我々は、ネットワーク内で合意に達していないピアへの報酬を制限する「インセンティブ」関数 I(W,S) による結託を回避するために、単純なランキング手法を拡張しました。 ピアのグループがシステムの過半数を超えるステークを保有しないと仮定すると、ピアは過半数からの票を集めるために努力することによってのみインフレを達成できる。これは、ビットコインのような多くの分散型システムにおける中心的な前提である。用語を再度説明すると、インセンティブ メカニズムにはステーク ベクター S とウェイトのセット W が必要である。ここで、行はピア間ランキングである。 また、ウェイトから信頼行列 T を推測する。ここで、ピア i と j の間にゼロ以外のエッジがある場合に限り、 ti,j = 1 となる。
我々は、ネットワーク内で合意に達していないピアへの報酬を制限する「インセンティブ」関数 I(W,S) による結託を回避するために、単純なランキング手法を拡張しました。 ピアのグループがシステムの過半数を超えるステークを保有しないと仮定すると、ピアは過半数からの票を集めるために努力することによってのみインフレを達成できる。これは、ビットコインのような多くの分散型システムにおける中心的な前提である。用語を再度説明すると、インセンティブ メカニズムにはステーク ベクター S とウェイトのセット W が必要である。ここで、行はピア間ランキングである。 また、ウェイトから信頼行列 T を推測する。ここで、ピア i と j の間にゼロ以外のエッジがある場合に限り、 ti,j = 1 となる。
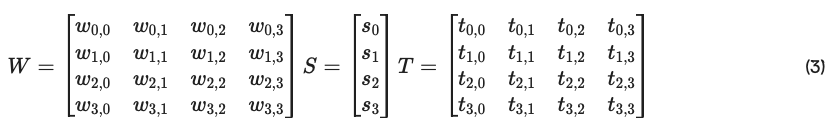
 我々は、「コンセンサス」に達したピアを、ネットワークの 50 パーセントを超えるステークからの非ゼロエッジを持つピアと定義する。(これは単純に(TT .S) > 0.5の正規化された値である) メカニズムが微分可能であることを保証するために、連続シグモイド関数を用いてこの計算を定義する。シグモイドは、接続されたピアに報酬を与え、信頼できないピアを罰する、しきい値のようなスケーリングを生成する。 急峻さと閾値点は、温度 ρ とシフト項 κ によって調整する。
我々は、「コンセンサス」に達したピアを、ネットワークの 50 パーセントを超えるステークからの非ゼロエッジを持つピアと定義する。(これは単純に(TT .S) > 0.5の正規化された値である) メカニズムが微分可能であることを保証するために、連続シグモイド関数を用いてこの計算を定義する。シグモイドは、接続されたピアに報酬を与え、信頼できないピアを罰する、しきい値のようなスケーリングを生成する。 急峻さと閾値点は、温度 ρ とシフト項 κ によって調整する。
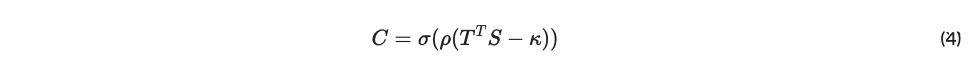
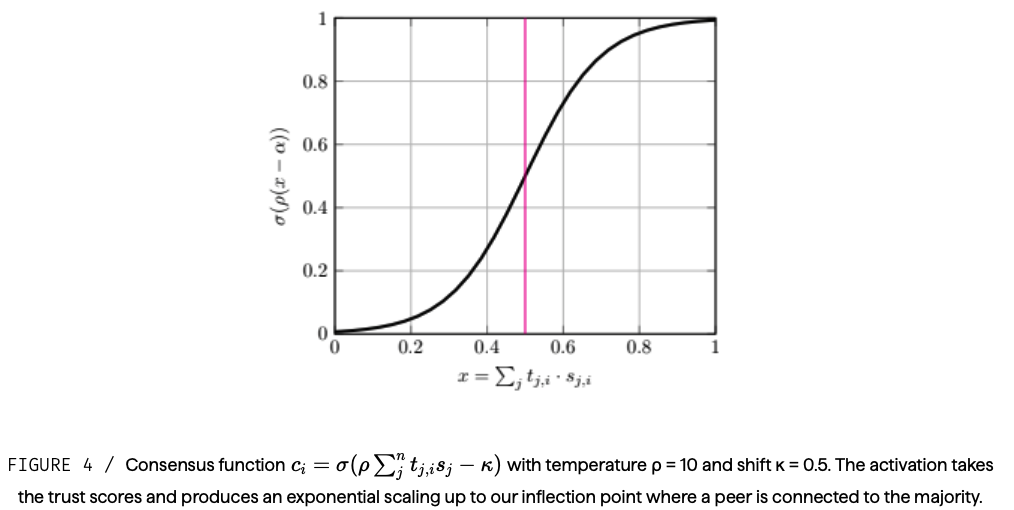
図4 / コンセンサス 関数ci = σ(ρΣnj tj,isj – k)、温度ρ = 10、シフトκ = 0.5。アクティベーションでは信頼スコアが取得され、ピアが多数派に接続される変曲点まで指数関数的にスケールアップされる。
 元のランキングを調整するためにコンセンサス用語を使用する。
元のランキングを調整するためにコンセンサス用語を使用する。
ピアがネットワーク内でより多くのウェイトを獲得すると、そのインフレは最大 0.5 まで指数関数的に増加する。 セクション 10 では、これにより、競合する 2 つのサブグラフのうち大きい方が、インフレーションを通じて指数関数的に大きな割合のネットワークを所有するようになる方法を示す。
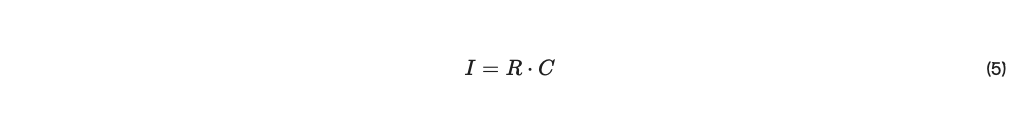
03 / Bonds 債券
 上述のこのコンセンサスは、小規模グループがインフレを達成することを困難にすることで、単純な結託を防ぐ。しかし、ウェイトを正しく選択するインセンティブはない。我々は、「債券」‘B’という形で投機ベースの報酬を伴うインフレ・メカニズムを適応させることによって、このようなインセンティブを導入する。ピアjの中でピアiが所有する債券の割合を示す。
上述のこのコンセンサスは、小規模グループがインフレを達成することを困難にすることで、単純な結託を防ぐ。しかし、ウェイトを正しく選択するインセンティブはない。我々は、「債券」‘B’という形で投機ベースの報酬を伴うインフレ・メカニズムを適応させることによって、このようなインセンティブを導入する。ピアjの中でピアiが所有する債券の割合を示す。
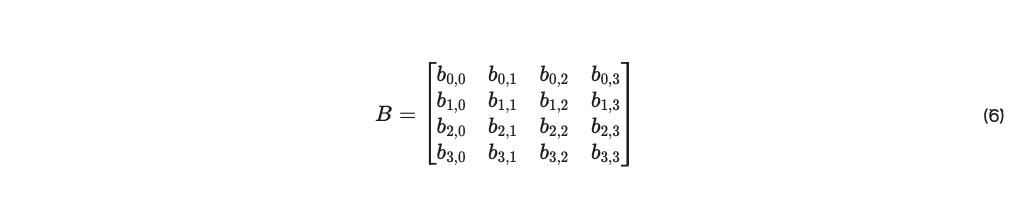
 債券は、ΔB=W⋅S のトークンインフレと同様に、各ステップで蓄積される。 このようにして、ピアはランク付けしたピア内に債権を蓄積し、接続されているピアと自分自身を「結合」する。
債券は、ΔB=W⋅S のトークンインフレと同様に、各ステップで蓄積される。 このようにして、ピアはランク付けしたピア内に債権を蓄積し、接続されているピアと自分自身を「結合」する。
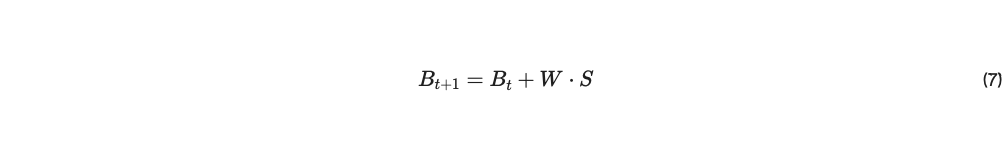
 B 債券マトリックスを使用して、チェーンは通常のインセンティブ スコア ΔS=BT⋅I を再分配する。 従来のステークに対する市場ベースの投機と同様、他の企業が後に評価するであろう他のピアに債券を蓄積した他のピアは、自らインフレ上昇を達成する。したがって、ピアが、システムに利害関係を持つ他のピアに応じてうまくいくと期待されるピア内に債券を蓄積し、その将来の価値を推測することは理にかなっている。最後に、このメカニズムをわずかに調整して、ピアが個人のインフレの一定割合を確実に達成できるようにする。たとえば、50 パーセント、ΔS = 0.5BTI + 0.5I。 ΔS は、n 個のピアにわたるネットワーク インセンティブを決定するメカニズム ステップ更新になる。
B 債券マトリックスを使用して、チェーンは通常のインセンティブ スコア ΔS=BT⋅I を再分配する。 従来のステークに対する市場ベースの投機と同様、他の企業が後に評価するであろう他のピアに債券を蓄積した他のピアは、自らインフレ上昇を達成する。したがって、ピアが、システムに利害関係を持つ他のピアに応じてうまくいくと期待されるピア内に債券を蓄積し、その将来の価値を推測することは理にかなっている。最後に、このメカニズムをわずかに調整して、ピアが個人のインフレの一定割合を確実に達成できるようにする。たとえば、50 パーセント、ΔS = 0.5BTI + 0.5I。 ΔS は、n 個のピアにわたるネットワーク インセンティブを決定するメカニズム ステップ更新になる。
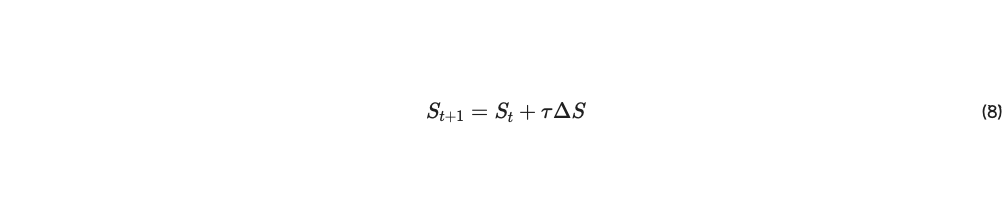
04 / Reaching consensus 合意形成
 セクション 2 のインセンティブ関数は、信頼性の高いピアに報酬を与えますが、公正なノードが合意に達しない場合、結託の問題を解決できない可能性がある。 著しく緩い、未使用のステーク、または不適切に設定されたウェイトは、結託しているサブネットワークと比較して、公正なピアのインフレ率を損なうことになる。公正なネットワークは、より多くのステークを保有しているものの、敵対者を圧倒するほどのインフレを獲得できない可能性がある。不公正なサブグラフは、ネットワークを完全に支配する必要はなく、最大の競合相手と競合するのに十分なインフレを達成するだけで十分である。
セクション 2 のインセンティブ関数は、信頼性の高いピアに報酬を与えますが、公正なノードが合意に達しない場合、結託の問題を解決できない可能性がある。 著しく緩い、未使用のステーク、または不適切に設定されたウェイトは、結託しているサブネットワークと比較して、公正なピアのインフレ率を損なうことになる。公正なネットワークは、より多くのステークを保有しているものの、敵対者を圧倒するほどのインフレを獲得できない可能性がある。不公正なサブグラフは、ネットワークを完全に支配する必要はなく、最大の競合相手と競合するのに十分なインフレを達成するだけで十分である。
 この攻撃は、トークンインフレの大部分が、グラフ内で過半数が信頼されていないピアに分配されている場合に発生する可能性がある。チェーンは、「損失期間」L = – R ・(C – 0.5)を通じてこれを測定できます(図7)。コンセンサスが0.5以上である他のピアにインフレの大半が分配されている場合、この期間はマイナスとなる。チェーンは損失計算をペグとして使用する。平均的なマイナーがネットワーク全体で設定するウェイトの数を増やすことで、チェーンはコンセンサスを確保できる。
この攻撃は、トークンインフレの大部分が、グラフ内で過半数が信頼されていないピアに分配されている場合に発生する可能性がある。チェーンは、「損失期間」L = – R ・(C – 0.5)を通じてこれを測定できます(図7)。コンセンサスが0.5以上である他のピアにインフレの大半が分配されている場合、この期間はマイナスとなる。チェーンは損失計算をペグとして使用する。平均的なマイナーがネットワーク全体で設定するウェイトの数を増やすことで、チェーンはコンセンサスを確保できる。

図5 / 左のネットワークはコンセンサスL>0と低く、50%以下のステークを持つ組織には抵抗力がない。チェーンは、L < 0になるまでピアによって設定されたエッジの数を増やしていく。この時点で、インフレの大部分は、多数派のコンセンサスを得たピアに流れる。
05 / Running the network ネットワークの実行
 ネットワーク内でピアを実行する手順は以下の通り:
ネットワーク内でピアを実行する手順は以下の通り:
- ピアはデータセットDiを定義する。
- 各反復トレーニングにおいて、ピアは条件付きでDi をピアに渡す x = [batch_size,sequence_length, input_size].
- レスポンス F(x) = […fj(x)…] – 各共通形状 fj(x) = [batch_size, sequence_length, output_size] – は、ゲート関数を用いて結合され、ローカルモデルfiの入力として使用される。
- ターゲットラベルとの比較により、損失勾配 ∂L/∂F が生成され、fi を介してネットワークに逆伝播される。
- 2 と 3 の間、ピアはピアによって生成された信号の値を測定することによって、行 wi,j ∈ W のウェイトを学習する。
- 異なるタイムステップ t で、参加者が重み ΔWi の変更を送信して、ランキング R、インフレ I、コンセンサス期間 C、および債券分配 δB を更新する。
- チェーンは「損失」を測定し、オプションで債券の所有権に応じて新しく発行されたステークをネットワークΔSに分配する。
06 / Tensor standardization テンソルの標準化
 さまざまなモデル タイプと入力タイプが相互作用するには、入力と出力の共通のエンコードが必要である。テンソルモダリティを使うことで、ネットワークを別々のグラフに分割することができる。最初は、単一のモダリティテキストでネットワークをシードし、その後、画像・音声・テンソルを含むように拡張することができる。最終的には、これらのモダリティを組み合わせて、例えばテキストと画像のようなものを追加し、ネットワークをマルチモダリティに橋渡しすることができる。モダリティを接続するためのインセンティブは、セクション (2) で提案されているのと同じ信頼スケーリングと統合できる。最終的には、成功するモデルはあらゆるモダリティからの入力を受け入れ、それらを処理して有用な表現にする必要がある。一貫性を保つために、言語モデルや画像モデルが生成する一般的なテンソル形状のように、ネットワーク全体で標準的な出力形状[batch_size, sequence_dim, output_dim]を使用し、ネットワークが複雑になるにつれてこのサイズを拡張することができる。
さまざまなモデル タイプと入力タイプが相互作用するには、入力と出力の共通のエンコードが必要である。テンソルモダリティを使うことで、ネットワークを別々のグラフに分割することができる。最初は、単一のモダリティテキストでネットワークをシードし、その後、画像・音声・テンソルを含むように拡張することができる。最終的には、これらのモダリティを組み合わせて、例えばテキストと画像のようなものを追加し、ネットワークをマルチモダリティに橋渡しすることができる。モダリティを接続するためのインセンティブは、セクション (2) で提案されているのと同じ信頼スケーリングと統合できる。最終的には、成功するモデルはあらゆるモダリティからの入力を受け入れ、それらを処理して有用な表現にする必要がある。一貫性を保つために、言語モデルや画像モデルが生成する一般的なテンソル形状のように、ネットワーク全体で標準的な出力形状[batch_size, sequence_dim, output_dim]を使用し、ネットワークが複雑になるにつれてこのサイズを拡張することができる。
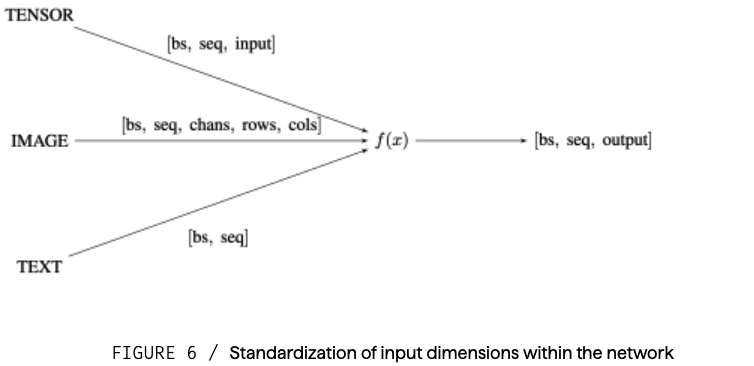
図6 / ネットワーク内の入力寸法の標準化
 抽象的な入力クラスに取り組むことで、参加者が一般的なマルチタスク理解に向けて取り組むことを確実にすることができる。カイザー他[2017]
抽象的な入力クラスに取り組むことで、参加者が一般的なマルチタスク理解に向けて取り組むことを確実にすることができる。カイザー他[2017]
参加者は、(2)全く異なるコンピューティング基盤Nugent and Molter [2014]、(2)データセットLample and Conneau [2019]、(3)モデル、および(4)市場でインセンティブを最大化するための戦略を使用することができる。ピアにとって、データが安価でプライバシーが要求されない非監視データセットに取り組むことは理にかなっている。
07 / Conditional computation 条件付き計算
 ネットワークが拡大するにつれて、送信帯域幅が大きなボトルネックになる可能性がある。ネットワーク転送を削減する必要性とピアを選択する方法が求められる。条件付き計算は、ピアが勾配降下法を通じてネットワーク内の近隣ノードを選択してプルーニングする方法を学習する場合に使用できる。
ネットワークが拡大するにつれて、送信帯域幅が大きなボトルネックになる可能性がある。ネットワーク転送を削減する必要性とピアを選択する方法が求められる。条件付き計算は、ピアが勾配降下法を通じてネットワーク内の近隣ノードを選択してプルーニングする方法を学習する場合に使用できる。
たとえば、プロダクトキーレイヤーや、まばらにゲートされたレイヤーなどです。シーザー他[2017]

 条件付きレイヤーは、各例に対してクエリするピアのまばらな組み合わせを決定し、それらを乗算的に再結合し、各例に対してピアの小さなサブセットのみをクエリすることで外部への帯域幅を削減する。この方法は、外向きの帯域幅を大幅に広げることができる。シーザー他[2017],リャビーニンとグセフ[2020]
条件付きレイヤーは、各例に対してクエリするピアのまばらな組み合わせを決定し、それらを乗算的に再結合し、各例に対してピアの小さなサブセットのみをクエリすることで外部への帯域幅を削減する。この方法は、外向きの帯域幅を大幅に広げることができる。シーザー他[2017],リャビーニンとグセフ[2020]
ピアがグラフ内のより多くの隣人と通信できるようにする。要するに、このレイヤーは、入力に基づくピアのためのトレーニング可能なDNSルックアップとして機能する。さらに、損失に関して学習可能であるため、ウェイト wi,j ∈ W の有用な代用となる。
08 / Knowledge extraction 知識の抽出
 関数間の依存関係により、モデルはオンラインのままである必要があり、実稼働環境で実行することはできない。この依存関係を解消するには、次のような方法がある。ヒンストン他[2015]
関数間の依存関係により、モデルはオンラインのままである必要があり、実稼働環境で実行することはできない。この依存関係を解消するには、次のような方法がある。ヒンストン他[2015]
より小さなモデル (学生) が残りのネットワークの動作を再現する圧縮および知識抽出テクニック。抽出レイヤーは、条件計算(10)レイヤーと組み合わせて使用され、学生モデルは、ゲーティングネットワークによって生成されたロジットと学生が予測したロジットとの間のクロスエントロピー(以下、KLとして示す)を使用して、ネットワークを再現するように学習する。サン他[2020]
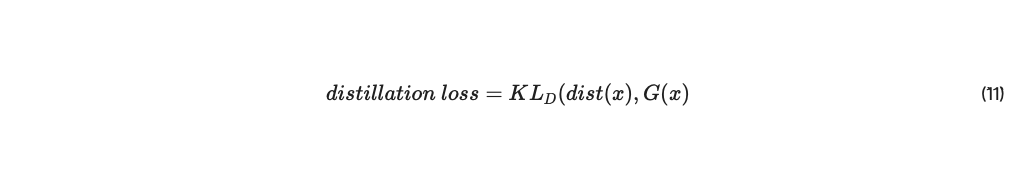
 抽出されたモデルはネットワークの代理として機能するため、モデルは完全にオフラインで評価することができる。ネットワークを介した再帰性は、任意のネットワークグラフを可能にするコンポーネント間でもカットされる。もしモデルがオフラインになったとしても、そのモデルのピアは抽出されたバージョンをそのまま使うことができる。プライベートデータ6は、ネットワークにクエリする代わりに、抽出されたモデル上で検証することができる。最終的にコンポーネントは、抽出されたモデルを使ってネットワークから完全に切り離し、オフラインで検証と推論を行うことができる。
抽出されたモデルはネットワークの代理として機能するため、モデルは完全にオフラインで評価することができる。ネットワークを介した再帰性は、任意のネットワークグラフを可能にするコンポーネント間でもカットされる。もしモデルがオフラインになったとしても、そのモデルのピアは抽出されたバージョンをそのまま使うことができる。プライベートデータ6は、ネットワークにクエリする代わりに、抽出されたモデル上で検証することができる。最終的にコンポーネントは、抽出されたモデルを使ってネットワークから完全に切り離し、オフラインで検証と推論を行うことができる。
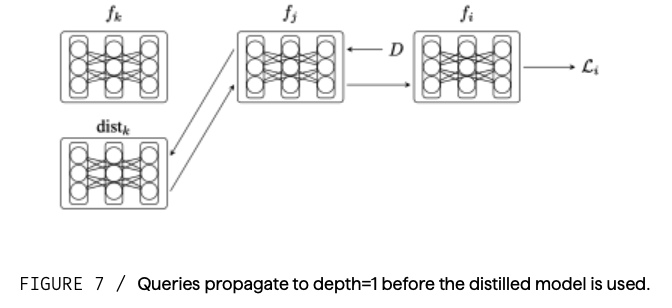
図7 / クエリは、抽出されたモデルが使用される前に、depth=1 まで伝播する。
09 / Learning weights 学習ウェイト
 この研究における我々の目標は、ピアに対するランキング r = [ri] を生成することです。ここで スコア ri ∈ R は、ベンチマークに対する参加者の情報理論的な重要性を表す。ルカンとルカン他に続く[1989];Yu et al. [2017],この重要性は、各ピアをネットワークから排除するコストと等しくすることで定義するのが妥当である。このスコアは、i 番目のピアがネットワークから削除されたときの ΔF(x)i が j 番目のピアの入力の摂動である場合、分析的に導出できまる (付録 12.2) :
この研究における我々の目標は、ピアに対するランキング r = [ri] を生成することです。ここで スコア ri ∈ R は、ベンチマークに対する参加者の情報理論的な重要性を表す。ルカンとルカン他に続く[1989];Yu et al. [2017],この重要性は、各ピアをネットワークから排除するコストと等しくすることで定義するのが妥当である。このスコアは、i 番目のピアがネットワークから削除されたときの ΔF(x)i が j 番目のピアの入力の摂動である場合、分析的に導出できまる (付録 12.2) :
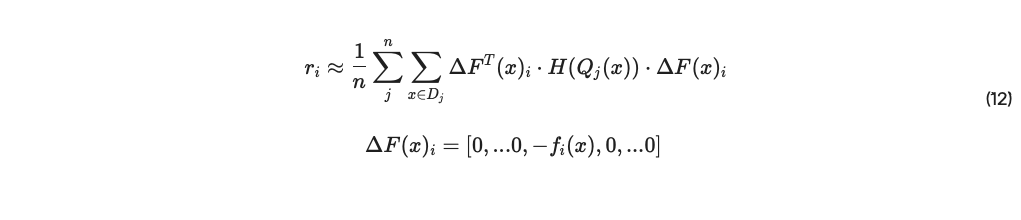
 誤差関数 Qj が 2 回微分可能なクロスエントロピーである場合、H(Qj) はそのフィッシャー・インフォメーション・マトリックスであり、ri ∈ R はネットワーク全体に対する各ピアの情報的重要性として適切に測定される。ただし、情報理論的なウェイトには、誤差の完全なヘシアンが必要です。実際には、誤差関数から入力に貢献スコアを伝播させるヒューリスティックを使用する方が合理的である。Yu他[2017].
誤差関数 Qj が 2 回微分可能なクロスエントロピーである場合、H(Qj) はそのフィッシャー・インフォメーション・マトリックスであり、ri ∈ R はネットワーク全体に対する各ピアの情報的重要性として適切に測定される。ただし、情報理論的なウェイトには、誤差の完全なヘシアンが必要です。実際には、誤差関数から入力に貢献スコアを伝播させるヒューリスティックを使用する方が合理的である。Yu他[2017].
例えば、ゲーティング・レイヤー(セクション6)からのウェイトは、微分可能な代用品として役に立つ。
10 / Collusion 結託
 我々は、ネットワーク内のピアの一部が「組織」を形成しているシナリオを考える: 近隣のピアを正確にスコアリングすることなく、自分たちのインフレを最大化しようとする結託したピアのセットである。ステーク SA を持つ公正なグラフ A と、ステーク SB を持つ分裂した組織 B の戦いは、それぞれが持つネットワークのステーク比率によって決定することができる。公正なグラフは、その優位性を維持し、ネットワークIA >> IBを保護するために、より多くのインフレを達成しなければならない。
我々は、ネットワーク内のピアの一部が「組織」を形成しているシナリオを考える: 近隣のピアを正確にスコアリングすることなく、自分たちのインフレを最大化しようとする結託したピアのセットである。ステーク SA を持つ公正なグラフ A と、ステーク SB を持つ分裂した組織 B の戦いは、それぞれが持つネットワークのステーク比率によって決定することができる。公正なグラフは、その優位性を維持し、ネットワークIA >> IBを保護するために、より多くのインフレを達成しなければならない。
 我々は、公正なグラフのステークの割合が不公正なグラフのSA >> SBよりも多く、チェーンがコンセンサスに達したと仮定する L < 0、 Bのすべてのピアは A から分離されているので、 損失期間 – RB ・ (CB – 0.5) > 0 は正である。なぜなら、L < 0 なので、RA・(CA – 0.5) < 0は負であり、公正なサブグラフ A には多数派に接続しているピアも存在する。
我々は、公正なグラフのステークの割合が不公正なグラフのSA >> SBよりも多く、チェーンがコンセンサスに達したと仮定する L < 0、 Bのすべてのピアは A から分離されているので、 損失期間 – RB ・ (CB – 0.5) > 0 は正である。なぜなら、L < 0 なので、RA・(CA – 0.5) < 0は負であり、公正なサブグラフ A には多数派に接続しているピアも存在する。
 連鎖が進むにつれて、新たに発行されたステークは、I = R – T に比例して、インフレ率 τ で放出されます。重要なのは、ステークに対するインセンティブ関数の勾配は、公正なグラフと不公正なグラフの間の変曲点では正で超線形である。特に、δI/δS = 5/2、これは、各サブグラフが保有するステーク量が、次の繰り返しにおけるインフレの非線形変化を反映することを保証する。
連鎖が進むにつれて、新たに発行されたステークは、I = R – T に比例して、インフレ率 τ で放出されます。重要なのは、ステークに対するインセンティブ関数の勾配は、公正なグラフと不公正なグラフの間の変曲点では正で超線形である。特に、δI/δS = 5/2、これは、各サブグラフが保有するステーク量が、次の繰り返しにおけるインフレの非線形変化を反映することを保証する。
 当初は、SA > 0.5、SB < 0.5 であるため、サブグラフ A で放出されるステークの割合はサブグラフ B で放出される割合を上回り、サブグラフAのインセンティブはBに比べて超直線的に成長する。
当初は、SA > 0.5、SB < 0.5 であるため、サブグラフ A で放出されるステークの割合はサブグラフ B で放出される割合を上回り、サブグラフAのインセンティブはBに比べて超直線的に成長する。
その結果、ステークSB / SA + SB の比率は減少し、組織は時間を通して自分自身を維持するために、そのサブグラフに継続的にステークを追加する必要がある。
 我々は、継続的なインフレのもとで、競合するグラフ間のこの比率を考慮している。
我々は、継続的なインフレのもとで、競合するグラフ間のこの比率を考慮している。
Pythonコードに変換…


11 / Conclusion 結論
 我々は、信頼できる環境の外側の P2P ネットワーク上で動作するインテリジェンス マーケットを提案した。 重要なのは、このベンチマークは、他のインテリジェンス システムを使用して表現知識の生産としてのパフォーマンスを測定し、その価値を決定することである。 これが協調的かつ高解像度の方法で実行できるという事実は、ベンチマークが一般にこの分野により良い報酬メカニズムを提供できる可能性があることを示唆している。
我々は、信頼できる環境の外側の P2P ネットワーク上で動作するインテリジェンス マーケットを提案した。 重要なのは、このベンチマークは、他のインテリジェンス システムを使用して表現知識の生産としてのパフォーマンスを測定し、その価値を決定することである。 これが協調的かつ高解像度の方法で実行できるという事実は、ベンチマークが一般にこの分野により良い報酬メカニズムを提供できる可能性があることを示唆している。
この目的を達成するために、このホワイトペーパーは、抽象的に定義されたインテリジェンス モデルで構成される P2P ネットワークの定義から始めた。 このフレームワークを使用して、ネットワークからピアをプルーニングするコストに基づいて各ピアのランキングを生成する方法を示した。 ピアは、デジタル台帳の一連の重みを使用してこのスコアを交渉した。 しかし、このシステムは、参加者が不公正なサブグラフを形成することを防ぐメカニズムがなければ不完全だった。
この問題を解決するために、ネットワークの大部分から信頼されているピアに指数関数的に報酬を与えるピア接続に基づくインセンティブ スキームを提案した。 これにより、時間の経過とともに、不公正なサブグラフが無関係に減衰することが保証された。
これに続いて、(1) ピアが差分レイヤーを使用して接続を学習することでネットワーク帯域幅を削減する方法、(2) 完全にネットワークに切断された機械学習モデルを抽出して実稼働環境で実行する方法を示した。 その結果、知識を生み出し、システム内の新しい学習者がそれを利用できるようにする参加者に報酬を与えるインテリジェンス市場が実現した。
このホワイトペーパーの原本(PDF)はこちら
Bittensor – whitepaper
こちらの記事もどうぞ

